 admin
admin
什么是真实在场正负值?
顾名思义,真实在场正负值(RPM)与数据统计单上的在场正负值(+/-)有着家族类似性,多了一个“真实”,意义大不相同,因为在场正负值只显示每个球员在场上时其效力球队的净胜分(或正或负)。
RPM的诞生受到了在场正负值以下这一逻辑的启发:如果一名球员在场上时,他的球队比对手得分更多,那么不管他有没有打出华丽的数据,他都可能做了些什么对球队有帮助的事情。
但我们所熟悉的在场正负值有个严重漏洞:每个球员在场上的队友们是谁、其队友发挥是好是坏,严重影响着他自己的正负值数值。
举个例子,如果我们看在场正负值数据,雷霆替补后卫雷吉-杰克逊排名联盟第27位,但他在场上的大部分时间里都和MVP凯文-杜兰特一起打球。我们真正想知道的是,杰克逊的优异数据到底有多少是他自己打出来的,而我们从在场正负值中根本得不到答案。
附:RPM的由来
真实在场正负值(RPM)由前菲尼克斯太阳队数据分析师昂热尔曼开发,与堪萨斯大学心理学教授、前NBA顾问师斯蒂夫-艾拉迪合作完成。
RPM在几位分析师提出的修正正负值(APM)和乔-斯蒂尔提出的正则化修正正负值(R-APM)的基础上进一步发展而来。
相比RAPM,昂热尔曼对RPM进行了诸多改进,其中用到了贝叶斯先验值、衰老曲线、比赛比分,以及大量的样本外检验,从而改进了RPM的预测精确度。
真实正负值从何而来?
凭借先进的统计建模技术(以及RPM的提出者、前菲尼克斯太阳队分析师昂热尔曼在数据分析上的魔力),这项数据指标通过针对每个队友和对手作出调整,成功分离出每一个NBA球员单独的正负值贡献。
RPM模型对每个赛季超过230,000个攻守回合进行筛选,梳理出场上每个球员对于该球员真实正负值的影响,所采用的技术跟那些需要同时分析大规模变量的科研人员所采用的建模技巧很相似。
RPM估算出一个球员在场上时,每100个回合平均下来是增加了球队每100回合净胜分还是减少了。RPM模型还通过分门别类来衡量球员在攻防两端的影响,也就是进攻真实正负值(ORPM)和防守真实正负值(DRPM)。
RPM最为衡量球员的重要的进阶数据,本文基于NBA2016-2017赛季球员数据来分析RPM的影响因素,为更好的评估球员的RPM来打下基础。
1.基础性数据分析
2.我们将球员的技术统计进行分类来分析对球员的RPM影响:球员的基础数据球员的进攻数据球员的防守数据
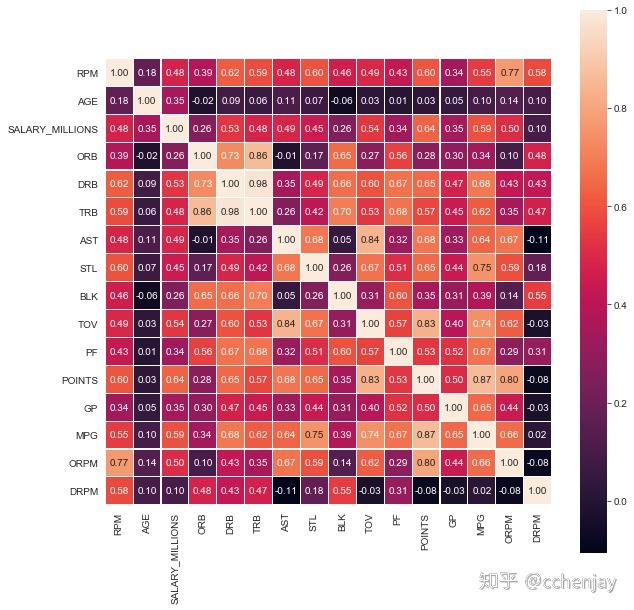
3. 我们将球员的技术统计进行组合分析对球员的RPM影响,并采用各种EDA(探索性数据分析)工具进行分析
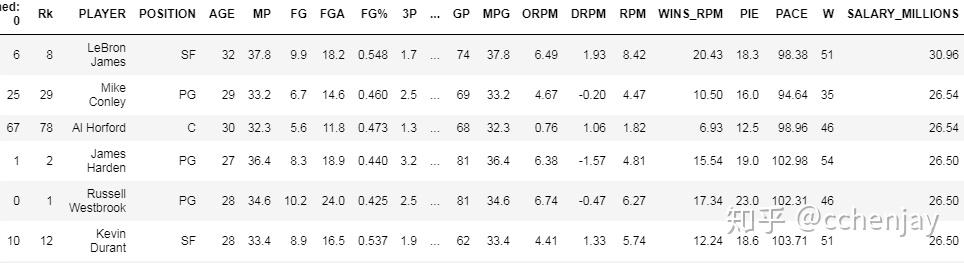
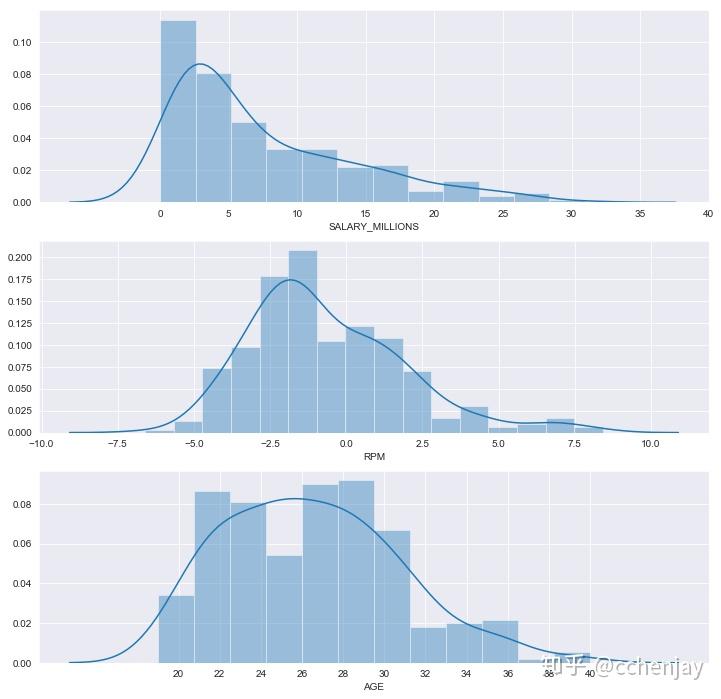
 工资最高的10名运动员:
工资最高的10名运动员:
效率值最高的10名运动员:
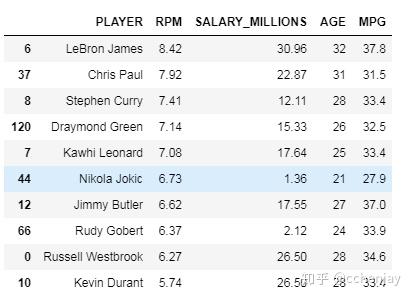 出场时间最高的10名运动员:
出场时间最高的10名运动员:
除了防守和进攻,球员的RPM是否与他们的总上场时间相关?
根据上面的回归图,它看起来好像在更高RPM和更多的上场时间之间有关联。然而,球员上场时间的增加是一种权衡。有人可能会说,如果一个球员在比赛中表现不佳(大量失误、错失球和犯规),他们的RPM实际上会下降。
让我们评估一下这种关系的强度:
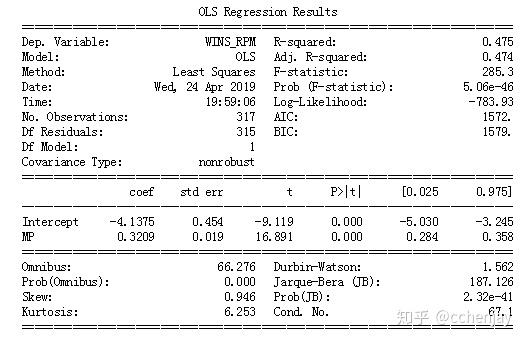 虽然我们观察到一个弱的正相关(Adj R-squared=0.481),但总的比赛时间可能不是一个球员的RPM的最佳预测值。让我们再看一看这个分析,并加上位置。从这里可以使用变量转换来帮助增强线性回归模型。球员的位置和上场时间是否可能提供一些额外的信息?
虽然我们观察到一个弱的正相关(Adj R-squared=0.481),但总的比赛时间可能不是一个球员的RPM的最佳预测值。让我们再看一看这个分析,并加上位置。从这里可以使用变量转换来帮助增强线性回归模型。球员的位置和上场时间是否可能提供一些额外的信息?
SSE(和方差、误差平方和):The sum of squares due to errorMSE(均方差、方差):Mean squared errorRMSE(均方根、标准差):Root mean squared errorR-square(可决系数R平方):Coefficient of determinationAdjusted R-square(调整后的可决系数R平方):Degree-of-freedomadjusted coefficient of determinationSSE,MSE和RMSE:越接近于0,越说明模型的选择与拟合越成功。R-square,Adjusted R-square:越接近1,越说明模型的选择与拟合越成功。正常取值
现在,我们考虑了球员的位置和在他们的上场时间,我们可以看到一些非常有趣的发现:在球员的RPM的上层没有得分后卫。小前锋和控球后能打出最高的RPM。在最精英的群体中,只有一个大前锋。在为球队的胜利做出贡献时,得分后卫和大前锋是否被边缘化了?看起来是这样的,这也符合联盟的现状,控卫和小前锋的天下,让我们把注意力重新转移到针对特定的防守和进攻性统计数据,这些数据与球员的RPM有关。
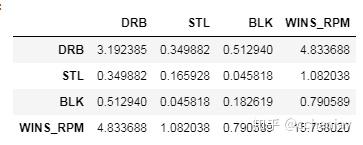
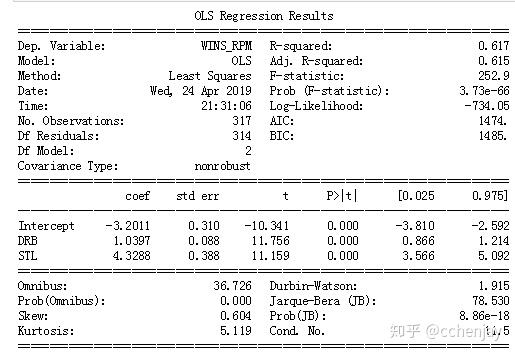 这两个自变量都反映了p值<0,我们显示的Adj R-squared=0.61。这通常被认为是一个适度的正相关,是预测一个球员的RPM的更好指标,而不是总的上场时间
这两个自变量都反映了p值<0,我们显示的Adj R-squared=0.61。这通常被认为是一个适度的正相关,是预测一个球员的RPM的更好指标,而不是总的上场时间
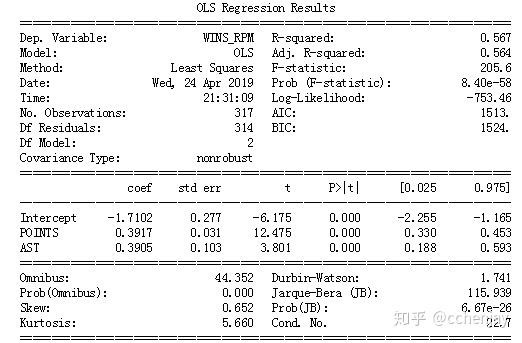 Adj. R-squared: 0.564 得分和助攻对个人效率的影响没有防守相关数据影响大,同时也比时间影响大
Adj. R-squared: 0.564 得分和助攻对个人效率的影响没有防守相关数据影响大,同时也比时间影响大
防守数据
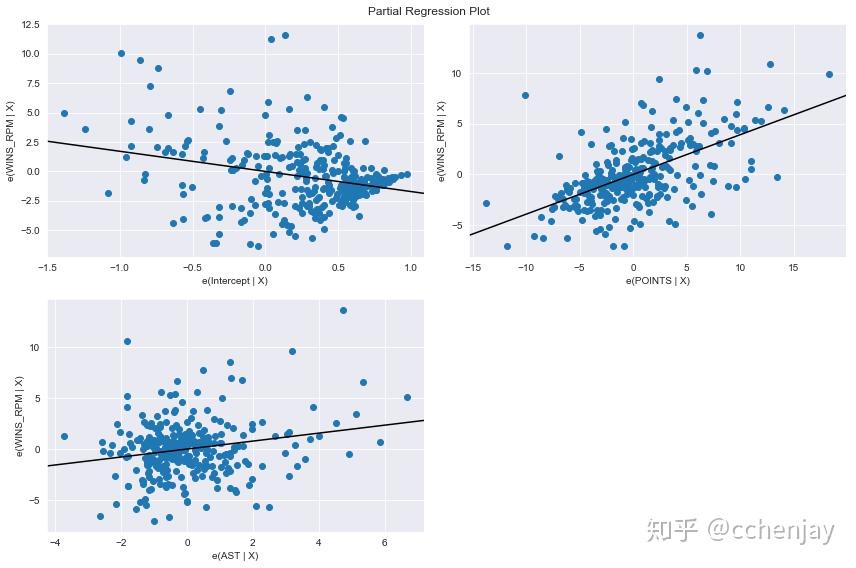 进攻数据
进攻数据
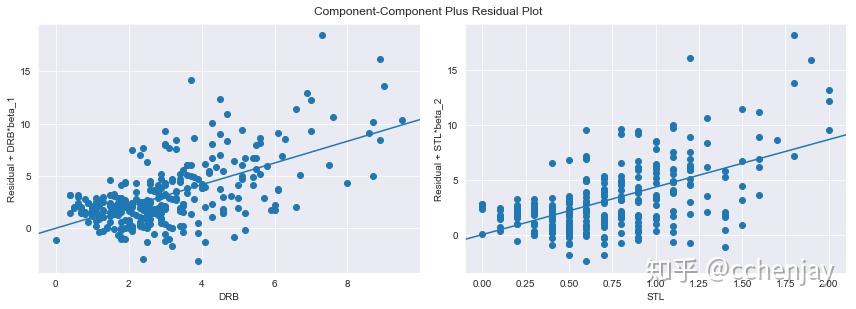 防守
防守
Homoskedastic(也拼写为“ homoscedastic ”)指的是回归模型中残差或误差项的方差恒定的条件。也就是说,随着预测变量的值改变,误差项变化不大。Homoskedasticity是线性回归建模的一个假设。如果回归线周围的误差方差变化很大,则回归模型可能定义不明确。缺乏同方差性可能表明回归模型可能需要包括额外的预测变量来解释因变量的性能。
让我们运行另一组回归诊断来进一步评估模型。
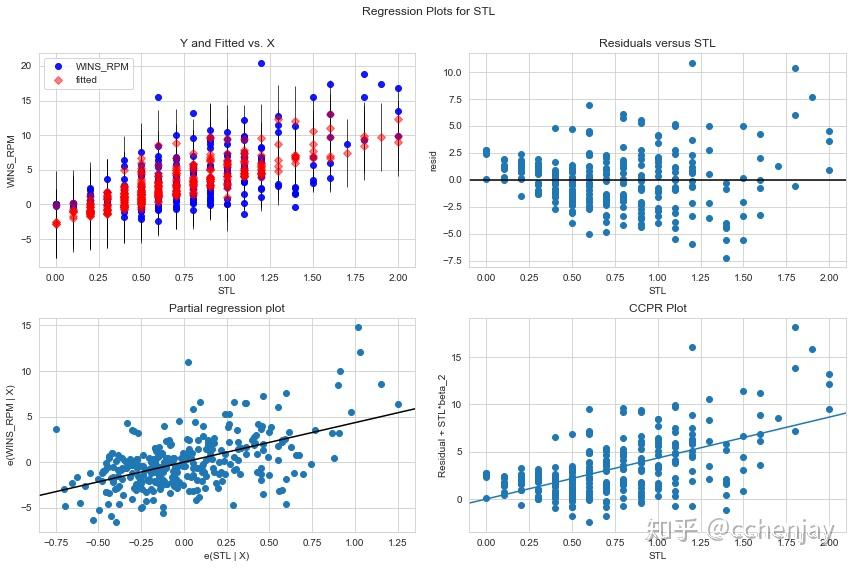 抢断
抢断
抢断
当抢断作为一个球员的RPM的唯一预测因素时,我们可以看到仍然有一个正相关。
然而,当我们将模型中的自变量数量限制为仅抢断时,我们可以看到Adj. R-squared显著下降,呈弱正相关。
现在可以假设盖帽和抢断相结合,相对于防守表现而言,这是对球员RPM更好的预测。
我将模型中变量变为的抢断、有效命中率、防守篮板、助攻、得分的组合、此时Adj. R-squared=0.689,这通常被认为是一个强烈的正相关,是预测一个球员的RPM的更好指标。
在为球队的胜利做出贡献时,得分后卫和大前锋是否被边缘化了,目前是控卫和小前锋的天下进攻数据可以较好的预测球员的RPM,但将防守数据和进攻数据结合可以更好的预测球员的RPM抢断、防守篮板、有效命中率、助攻、得分是预测RPM最主要的技术统计我们利用热图、散点图和回归模型诊断得出一个结论,得出一个观点,但确实需要进行额外的分析。
请关注公众号:数据人数据魂 ,谢谢各位友友们支持。

版权声明
本文仅代表作者观点,不代表xx立场。
本文系作者授权xx发表,未经许可,不得转载。



评论列表
发表评论